Cloud Enterprise Architecture, DevSecOps, Multi-CSP/Hybrid-Cloud, Data Migration
Background
A large U.S. Government Agency was moving to a centralized Enterprise GitHub during its digital transformation and DevOps journey. It is an authoritative source of truth for all code, including application code, infrastructure as code, as well as configuration and governance solutions. As more and more systems become dependent on a centralized version control system, the mission critical system must always be available, even in the event of a catastrophic regional failure or other disaster scenarios.
Analysis
Simple Technology Solutions (STS) assessed the current disaster recovery solution in place and identified the need for a more robust solution. In the event of a regional AWS failure, the suite of DevOps tools would need to be immediately accessible (source code repositories being of primary importance).Solution
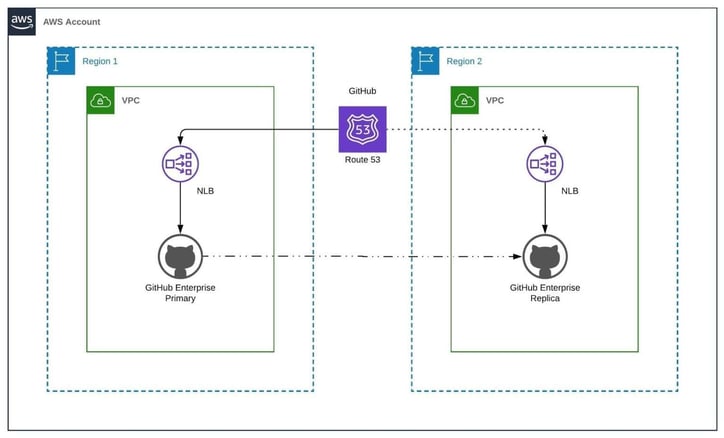
The GitHub Enterprise instance needed to be deployed into multiple regions in AWS. A primary GitHub instance asynchronously replicates to a replica instance in the secondary region. This solution will be deployed using an orchestration tool (Jenkins) and the infrastructure will be provisioned using Terraform. Ansible was used to configure the primary instance, its replica, and start synchronizing. In the event of a region failure or disaster recovery scenario, Domain Name System (DNS) health checks will point to the load balancer in the secondary region. Under these circumstances, the replica instance is promoted to become the new primary GitHub Enterprise instance.
Benefit
As enterprise environments adopt Agile and DevOps practices, there is a heavy reliance on their code repositories. Source control repositories house both infrastructure as code and application code, making them some of the most important resources in the enterprise besides their customer data. They need to be available 24/7, 365 days a year, with the lowest Recovery Point Objective (RPO) and Recovery Time Objective (RTO). These are the two of the most important parameters of a disaster recovery plan. By implementing the STS solution, an enterprise can expect its source code to be resilient and recoverable in the event of any failures or disasters.
Production Account Diagram
Providing Resiliency, Availability, and Disaster Recovery for Enterprise Source Code
Like what you're reading? Start a conversation by booking a meeting with us today.

Access our Proven Strategies for Agency Legacy Application Migration Ebook to learn about the challenges of a legacy application migration to the cloud, metrics for success, and more.



